Waymo Motion Forecasting
Repository: WaymoMotionEstimator
Technical Report: ConvMLP Paper
Project Overview
This project implements trajectory prediction models on the Waymo Open Motion Dataset (WOMD). Given 1 second of past agent motion (10 timesteps at 10 Hz), the models forecast 8 seconds of future positions (80 timesteps). Both models were trained on 250 TFRecord files (~25% of the WOMD training partition) using a GPU-accelerated Google Compute Engine VM, streaming data directly from Google Cloud Storage.
Two architectures are implemented: a single-mode baseline (ConvMLP) and a multi-modal extension (MultiModalConvMLP) that predicts 6 possible future trajectories with confidence scores. Both operate on individual agent tracks without map or scene context.
Results
| Model | Avg Loss | Avg ADE (m) | Avg FDE (m) |
|---|---|---|---|
| ConvMLP | 434.36 | 14.25 | 31.83 |
| MultiModalConvMLP (best-of-6) | 87.35 | 3.85 | 10.32 |
The multi-modal model achieves a 73% reduction in ADE and 68% reduction in FDE compared to the baseline, demonstrating that real-world motion is inherently multi-modal — a single predicted trajectory cannot capture the range of plausible futures (turning, lane changing, stopping), while offering six modes and selecting the best one dramatically improves accuracy.
Single-Mode Baseline:
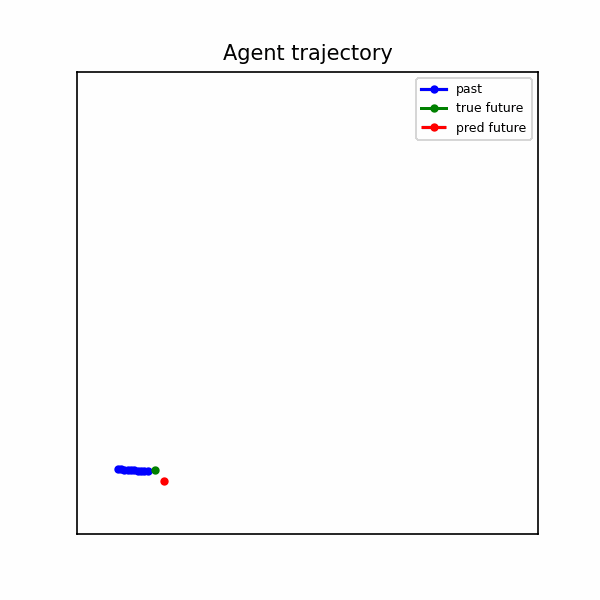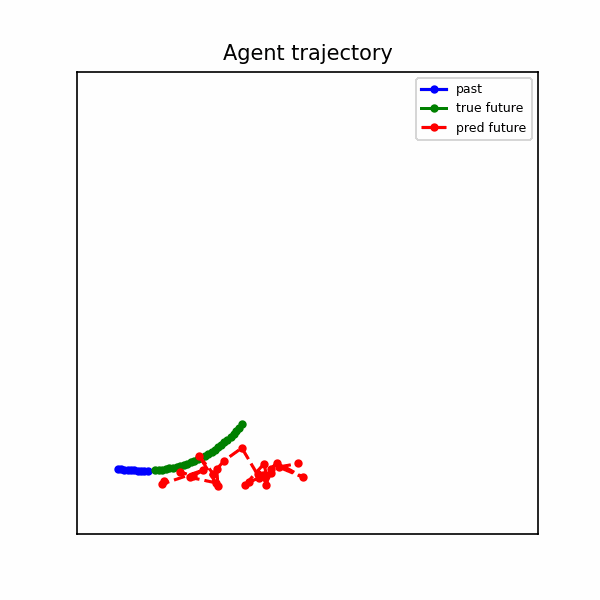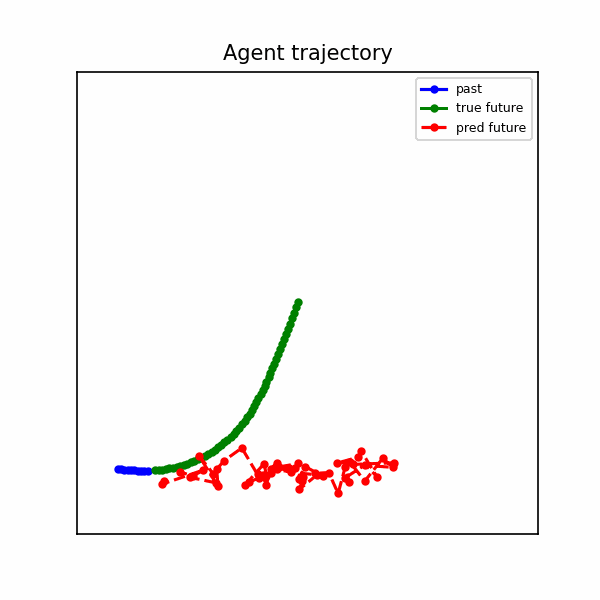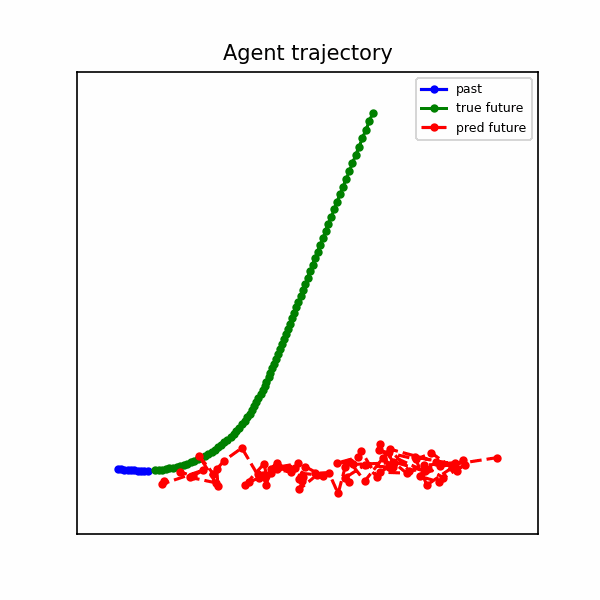
The baseline produces straight-line extrapolations that diverge when the agent turns or brakes.
Multi-Modal Predictions:
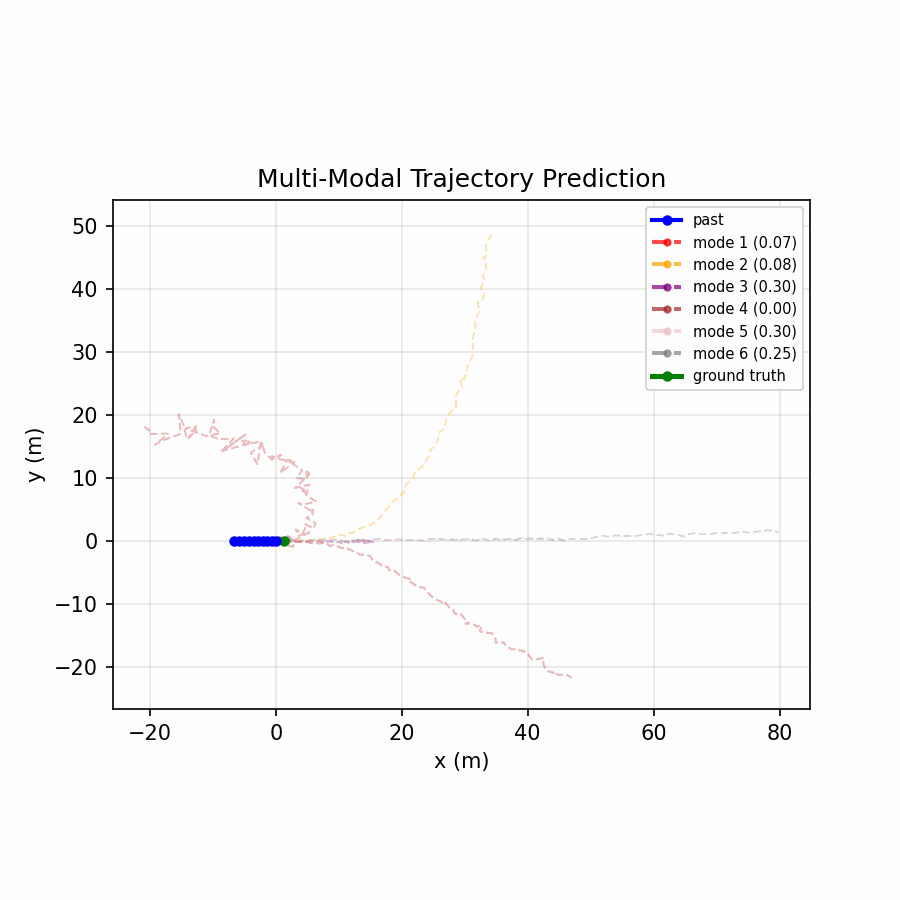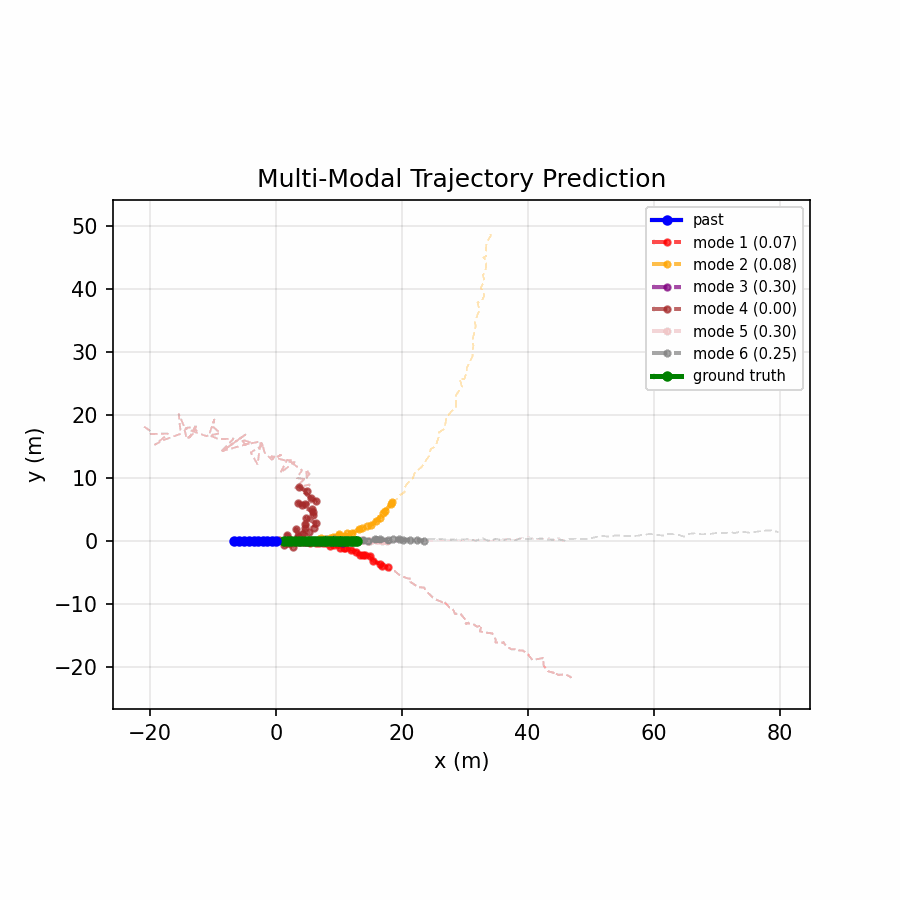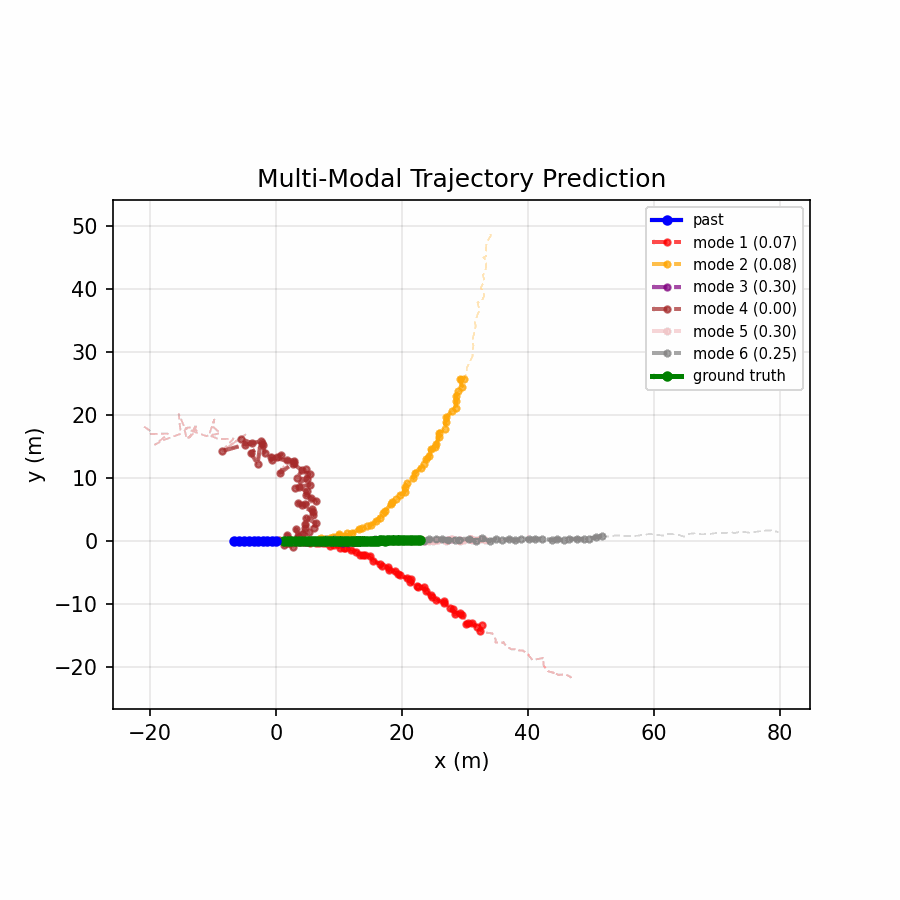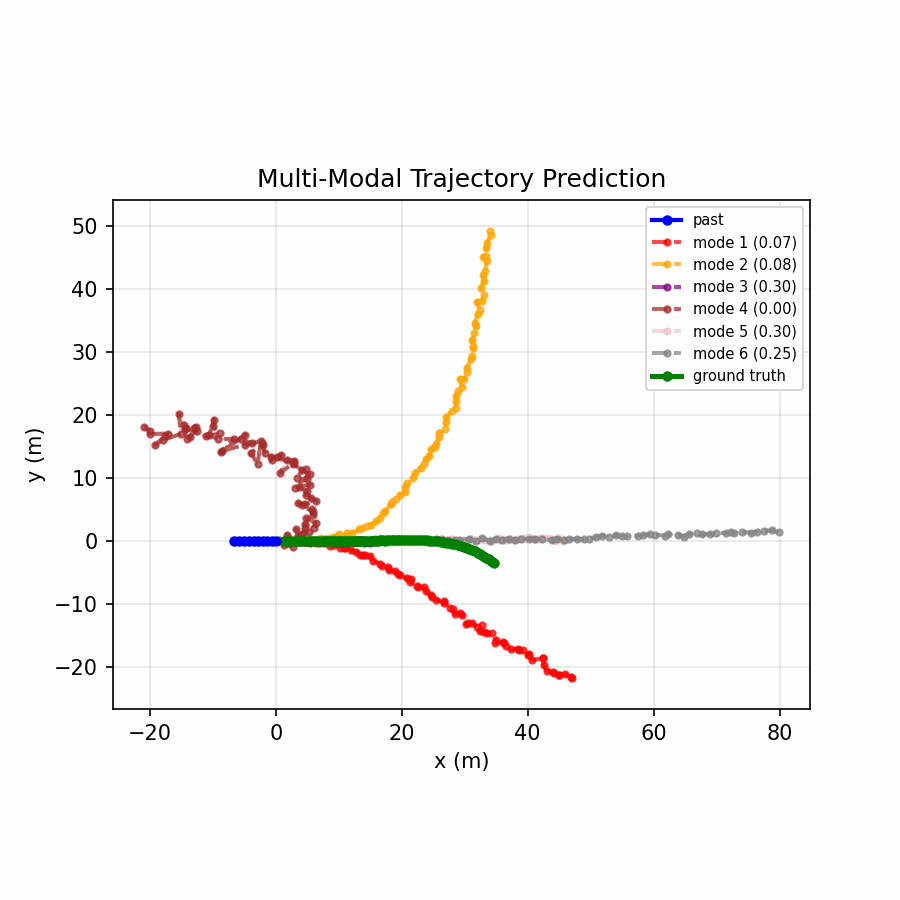
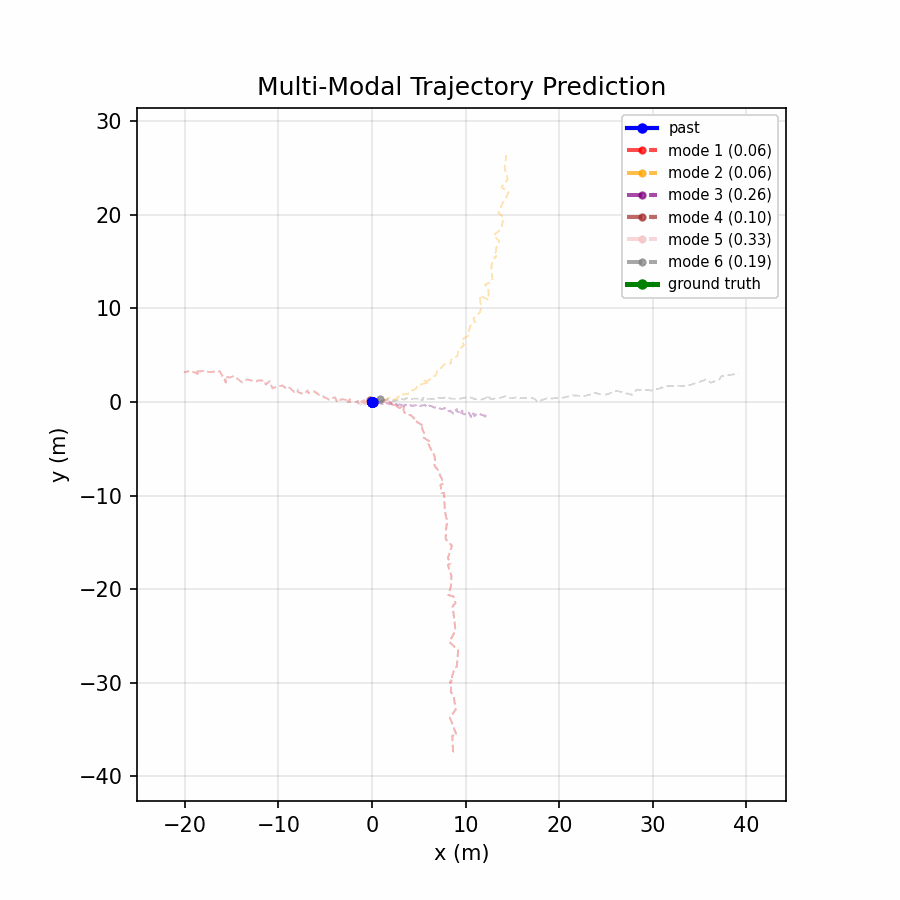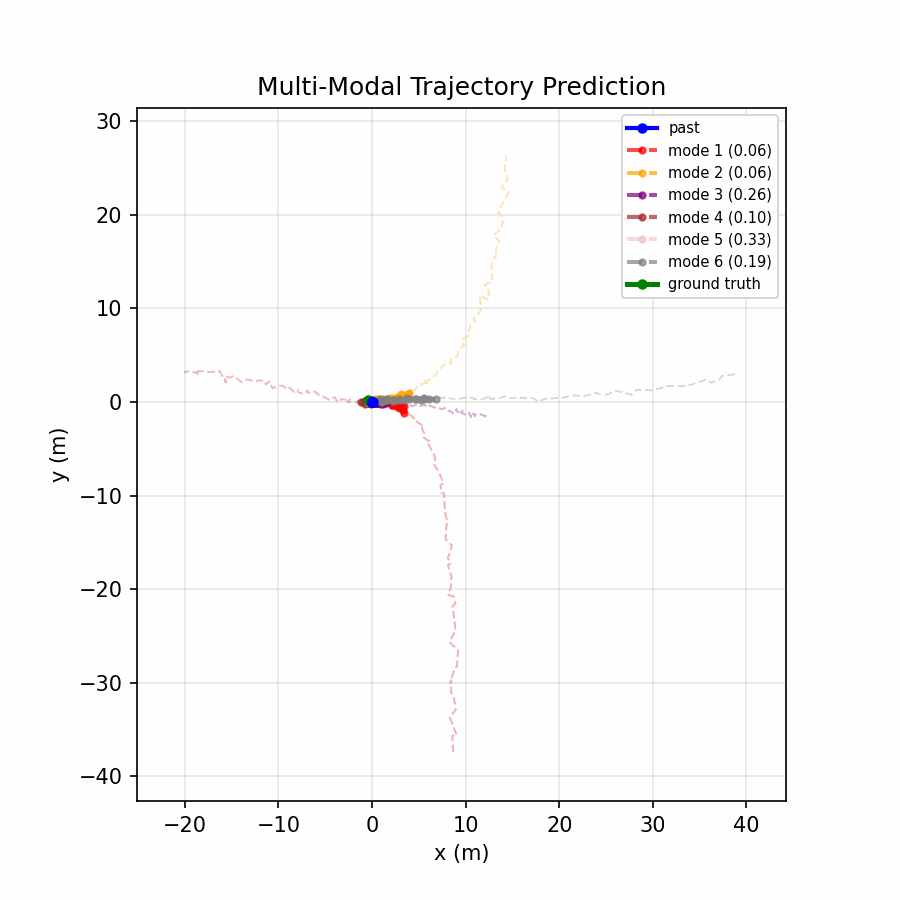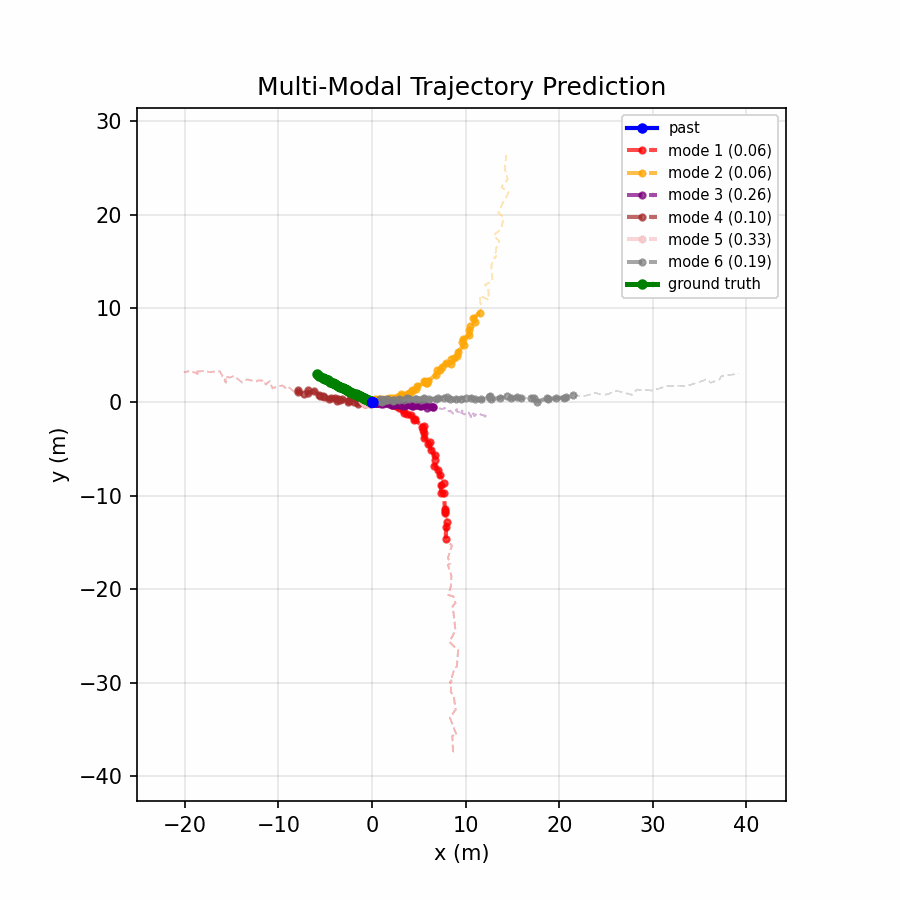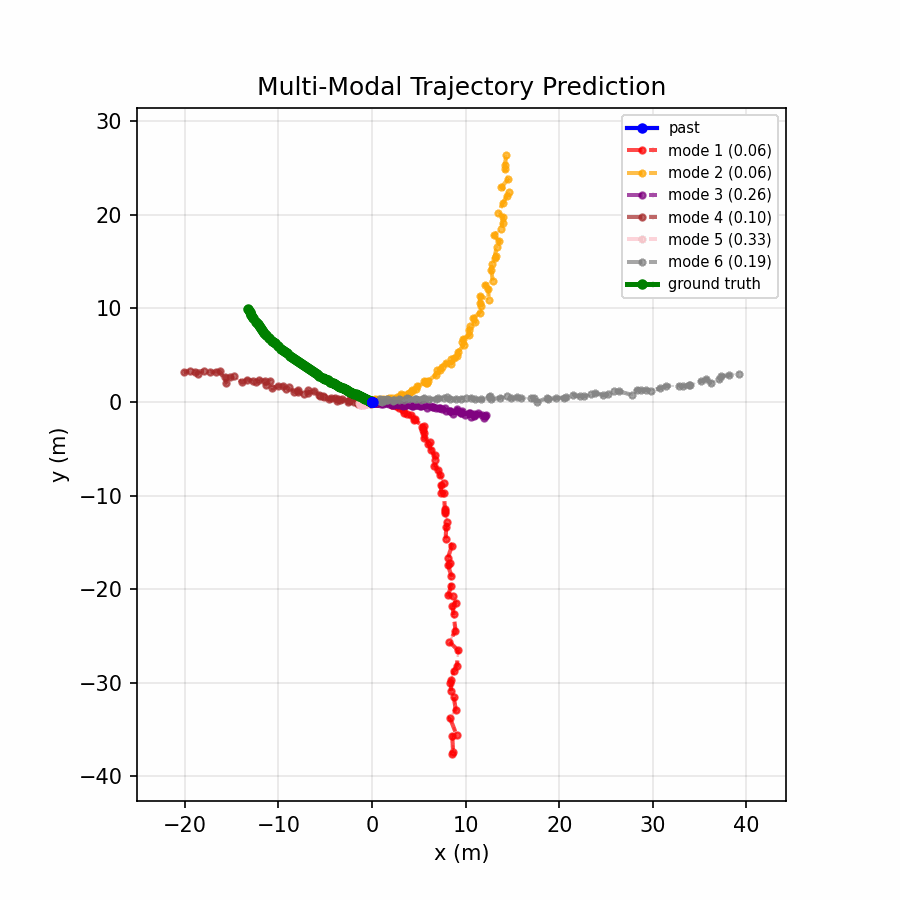
Six trajectory modes spread to cover distinct plausible futures, with the confidence head distributing probability across relevant modes.
My Contributions
- Designed and implemented both model architectures — a Conv1D + MLP baseline and a multi-modal extension with K=6 trajectory heads and a softmax confidence head.
- Built the full training infrastructure on GCP — provisioned a GPU VM, configured streaming data ingestion from Waymo’s public GCS bucket, and managed training runs via screen sessions with checkpoint management.
- Developed the winner-takes-all loss — combines a control loss (regression on the best-matching trajectory mode) with an intent loss (cross-entropy encouraging the confidence head to identify the correct mode).
- Identified and fixed a critical data preprocessing bug — the past validity mask was parsed but never applied, allowing agents with invalid past timesteps into training. This corrupted the coordinate normalization (which computes translation and rotation from the last observed positions), causing exploding predictions. The fix filters to agents with all past timesteps valid, which was essential for stable training. (See technical report for details.)
- Built the data pipeline — TFRecord parsing, coordinate normalization (translate to origin, rotate to align heading with +x axis), validity mask handling, and train/val splitting.
- Established config-based experiment management — YAML configuration files for reproducible experiments with automatic timestamped logging and checkpoint saving.
- Evaluation and visualization — ADE/FDE metrics with validity-aware computation, animated GIF generation comparing predicted vs. ground truth trajectories, and dynamic checkpoint resolution for evaluation.
Architecture Details
ConvMLP (Baseline): Two 1D causal convolution layers (64 filters, kernel size 3) encode the past trajectory, followed by a flatten layer and MLP decoder (128-unit hidden layer → 160-unit output reshaped to 80×2). Produces a single deterministic future trajectory.
MultiModalConvMLP: Shares the same convolutional encoder and a 128-unit shared feature layer. Six separate Dense heads each predict an independent (80, 2) trajectory. A softmax confidence head predicts the probability distribution over modes. Trained with winner-takes-all: only the closest mode to ground truth receives gradient, encouraging specialization across heads.
Tech Stack
- Python, TensorFlow/Keras
- Google Compute Engine (GPU VM with Tesla T4)
- Google Cloud Storage (streaming WOMD TFRecords)
- Conv1D + MLP architecture, multi-modal WTA loss
- YAML-based experiment configuration
- TensorBoard for training monitoring
- Docker for local reproducibility
Future Work
- Incorporate map and road graph context as model inputs
- Model agent-agent interactions (social forces, attention over neighbors)
- Explore Transformer and Graph Neural Network architectures
- Increase trajectory modes with improved loss balancing
- Investigate batch size sensitivity for WTA training at scale
Link: GitHub Repository